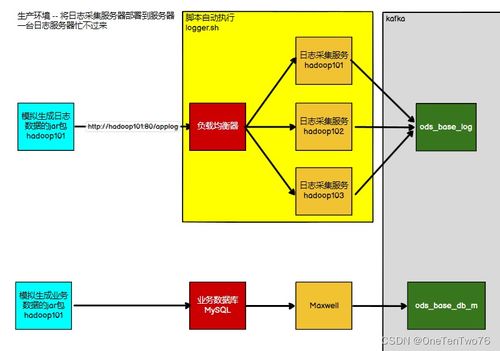
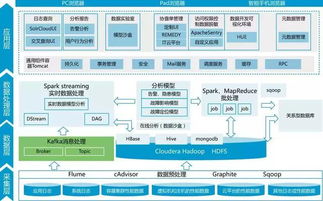
在B站这样日活用户过亿的平台中,数据处理服务作为大数据开发治理平台的核心模块,承担着海量数据的高效处理与价值挖掘任务。经过多年实践与迭代,我们在数据处理服务的设计上积累了一些重要心得。
数据处理服务的设计需以业务场景为导向。B站业务场景多样,涵盖视频推荐、弹幕分析、用户画像构建等多个维度。为此,我们设计了模块化的数据处理流水线,支持对不同数据源(如日志、数据库、流数据)的统一接入,并提供灵活的ETL(提取、转换、加载)工具。通过预置常用数据处理模板(如去重、聚合、关联),业务团队可快速构建数据流,无需重复开发。
性能与稳定性是数据处理服务的生命线。面对TB级甚至PB级的数据量,我们采用了分布式计算框架(如Spark、Flink)作为底层引擎,并结合B站特有的数据特征进行调优。例如,在实时数据处理场景中,我们优化了流处理任务的资源调度策略,确保在高并发下仍能维持毫秒级延迟。同时,通过监控告警、自动容错和重试机制,保障数据处理的可靠运行,避免因单点故障导致数据丢失或延迟。
第三,易用性与可扩展性是提升团队协作效率的关键。我们在数据处理服务中集成了可视化配置界面,用户可通过拖拽方式定义数据流程,降低技术门槛。服务支持插件化扩展,允许开发团队自定义UDF(用户定义函数)或集成第三方工具,以适应新兴业务需求。例如,针对AI模型训练的数据预处理,我们引入了TensorFlow Data Service的集成模块,简化了特征工程流程。
数据治理与安全贯穿于数据处理全过程。我们设计了数据血缘追踪功能,记录每个数据集的来源、变换和流向,便于问题溯源和影响分析。同时,通过权限控制和数据脱敏机制,确保敏感信息(如用户隐私)在数据处理中的合规性。
B站大数据开发治理平台的数据处理服务,成功融合了业务导向、高性能、易用性和治理安全等要素。未来,我们将继续探索智能化数据处理(如AutoML集成)和跨云混合部署,以应对更复杂的业务挑战,为B站生态提供更强大的数据支撑。