随着云计算的普及,云原生开发已成为现代软件构建的主流方式。它强调利用云平台的弹性、可扩展性和自动化能力,帮助团队高效交付应用。本指南将全面介绍云原生开发的核心概念,从容器到微服务,并深入探讨数据处理服务的关键角色,为开发者提供实践指导。
一、容器化:云原生开发的基石
容器是云原生架构的基础,它通过轻量级虚拟化技术将应用及其依赖打包成独立单元,确保环境一致性。Docker 是最流行的容器化工具,允许开发者在本地构建、测试镜像,然后部署到任何支持容器的平台。Kubernetes 作为容器编排系统,自动化管理容器的部署、扩缩容和故障恢复,是云原生生态的核心组件。通过容器化,团队可以快速迭代应用,减少环境冲突,提升开发效率。
二、微服务架构:解耦复杂系统的关键
微服务将单体应用拆分为多个小型、独立的服务,每个服务负责特定功能,并通过 API 进行通信。这种架构提高了系统的可维护性和可扩展性。在云原生环境中,微服务与容器天然契合:每个微服务可以封装在一个容器中,由 Kubernetes 统一编排。开发者可以使用服务网格(如 Istio)管理服务间的通信、负载均衡和安全策略。微服务的引入促进了团队协作,但也带来了分布式系统的挑战,如数据一致性和监控复杂性。
三、数据处理服务:云原生的数据驱动引擎
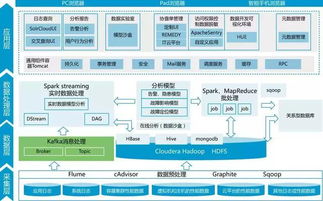
在云原生应用中,数据处理服务是不可或缺的部分,它支持实时流处理、批处理和数据分析。常见的数据处理工具包括 Apache Kafka 用于消息队列,Apache Spark 用于大数据处理,以及云原生数据库如 Amazon DynamoDB 或 Google Bigtable。这些服务与容器和微服务集成,提供高可用性和弹性伸缩能力。例如,在微服务架构中,事件驱动模式结合 Kafka 可以实现异步数据处理,提升系统响应速度。使用云原生数据湖(如 AWS S3)可以存储海量数据,并通过服务如 Apache Flink 进行实时分析。
四、全栈实践:构建端到端云原生应用
要构建完整的云原生应用,开发者需要整合容器、微服务和数据处理服务。实践步骤包括:使用 Docker 容器化应用组件;利用 Kubernetes 部署微服务集群,并配置服务网格来优化通信;集成数据处理服务,如通过 Kafka 处理事件流,或使用云数据库存储用户数据。监控和日志工具(如 Prometheus 和 Grafana)是必不可少的,它们帮助跟踪应用性能和数据处理指标。通过 DevOps 和 CI/CD 流水线,团队可以自动化测试和部署,确保快速交付。
五、挑战与未来展望
尽管云原生开发带来诸多优势,但也面临挑战,如安全性、成本管理和技能要求。未来,随着边缘计算和 AI 的融合,云原生数据处理服务将更智能化,支持更多实时场景。开发者应持续学习新技术,例如服务网格的演进和云原生数据库的创新,以适应不断变化的行业需求。
云原生开发从容器到微服务,再到数据处理服务,形成了一个完整的生态系统。通过掌握这些核心要素,团队可以构建高效、可靠的应用,推动数字化转型。本指南旨在为初学者和进阶开发者提供实用参考,助力在云原生旅程中取得成功。