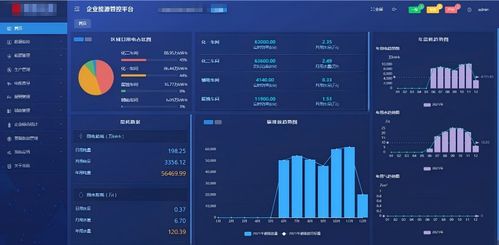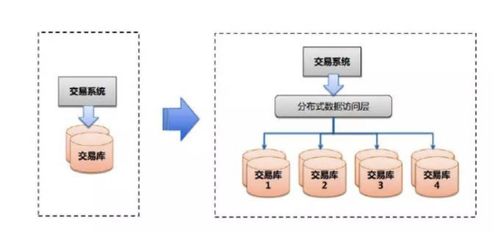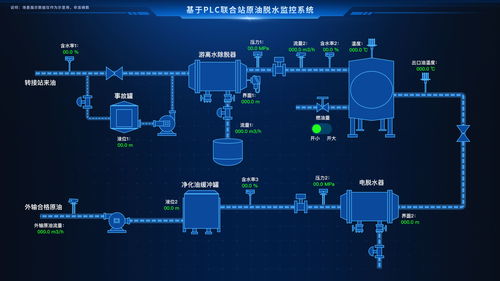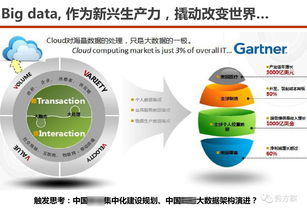
在数字化转型的浪潮中,数据中台已成为企业实现数据驱动的关键基础设施。一个通用的数据中台架构能够整合多源数据、提供统一的数据服务,并支持业务快速创新。本文将重点探讨数据处理服务在数据中台中的核心作用,并详细介绍如何构建一个高效、可扩展的数据处理架构。
一、数据中台架构概述
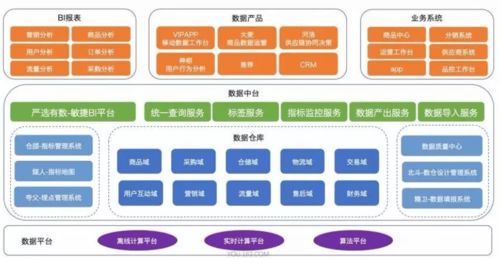
数据中台架构通常分为数据采集、数据存储、数据处理、数据服务和数据治理五大层次。数据处理服务作为核心环节,承担着数据清洗、转换、集成和计算的任务,确保数据质量与可用性。
二、数据处理服务的关键组件
- 数据集成与采集:通过ETL(抽取、转换、加载)或ELT工具,从业务系统、日志、第三方API等数据源实时或批量采集数据,并存入数据湖或数据仓库。
- 数据清洗与标准化:利用规则引擎或机器学习模型,处理数据中的噪声、缺失值和重复项,统一数据格式与标准,确保数据一致性。
- 数据计算与加工:基于分布式计算框架(如Spark、Flink)进行数据聚合、关联分析和特征工程,生成可供业务直接使用的数据模型。
- 数据质量监控:建立数据质量指标和告警机制,实时监测数据处理过程中的异常,保障数据的准确性与完整性。
三、构建通用数据处理架构的步骤
- 需求分析:明确业务场景与数据需求,例如实时报表、用户画像或预测分析。
- 技术选型:选择适合的存储(如HDFS、对象存储)和计算引擎(如Hadoop、Spark),并考虑云原生或混合部署方案。
- 流水线设计:构建可配置的数据处理流水线,支持批处理和流处理,实现低延迟与高吞吐。
- 服务化与API化:将数据处理能力封装为微服务或API,方便业务系统调用,提升数据复用性。
- 安全与治理:集成数据加密、权限控制和审计功能,遵循数据隐私法规(如GDPR)。
四、案例与最佳实践
以某电商企业为例,其数据中台通过数据处理服务整合了订单、用户和行为数据,实现了实时推荐和库存预测。关键经验包括:采用分层数据处理(原始层、明细层、汇总层),使用Kafka进行流数据摄取,并通过数据血缘工具追踪数据流向。
五、未来展望
随着AI和云技术的发展,数据处理服务将更智能化,例如通过自动优化计算资源、智能数据发现来降低运维成本。企业应持续迭代架构,以适应数据量的爆发式增长和业务多样化需求。
一个通用的数据中台架构依赖于强大的数据处理服务。通过模块化设计、技术融合和治理保障,企业能够释放数据价值,加速数字化转型。