随着大数据技术的快速发展,数据已成为知识服务的重要基础。原始数据往往存在各种质量问题,如不一致、重复、缺失和噪声等,这些都会影响后续知识提取和服务的准确性。因此,数据清理成为大数据处理的关键环节。本文以面向知识服务为背景,探讨大数据清理的方法和技术框架。
一、大数据清理的核心目标
数据清理的主要目标是提升数据质量,使其适合知识服务应用。具体包括:
- 一致性:消除数据中的逻辑矛盾。
- 完整性:补全缺失值或处理缺失数据。
- 准确性:纠正错误数据和异常值。
- 唯一性:去除重复记录。
- 时效性:确保数据反映最新状态。
二、面向知识服务的大数据清理技术框架
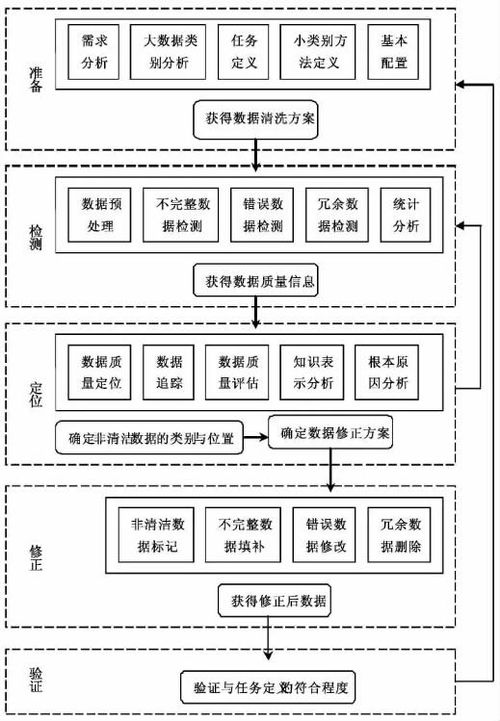
面向知识服务的大数据清理不仅关注基础数据质量,还需考虑知识表达和语义一致性。其技术框架通常包括以下层次:
- 数据获取与预处理层
- 从多源(如数据库、日志、传感器)采集数据。
- 进行格式统一、编码转换和初步过滤。
- 数据质量评估层
- 定义质量指标(如完整性率、一致性得分)。
- 利用统计分析、规则引擎评估数据问题。
- 核心清理处理层
- 重复数据检测与合并:使用相似度算法(如编辑距离、Jaccard系数)识别重复记录,并基于业务规则合并。
- 缺失值处理:根据场景选择删除、插补(均值、回归预测)或标记缺失。
- 异常值检测:通过统计方法(Z-score、IQR)或机器学习模型识别异常。
- 不一致纠正:利用规则库或知识图谱修正语义矛盾(如单位不统一、编码冲突)。
- 知识语义整合层
- 结合领域知识(如本体、 taxonomy)进行语义清理。
- 实体解析与链接,确保数据对象在知识服务中具有一致标识。
- 清理验证与优化层
- 通过抽样验证、用户反馈评估清理效果。
- 基于历史数据优化清理规则和参数。
三、数据处理服务在清理中的应用
数据处理服务为大数据清理提供可扩展、自动化的支持:
- 服务化接口:通过API或工作流引擎,将清理功能封装为服务,供知识服务系统调用。
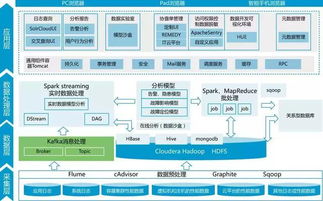
- 分布式计算:利用Hadoop、Spark等框架,实现海量数据的高效清理。
- 实时处理:结合流处理技术(如Flink),支持对动态数据的即时清理。
- 监控与管理:提供服务运行状态监控、清理日志和性能报告。
四、挑战与未来方向
尽管技术框架日益成熟,大数据清理仍面临挑战:
- 多源异构数据的语义集成。
- 实时清理的延迟与准确性平衡。
- 隐私保护与数据安全的兼顾。
未来,随着人工智能和知识图谱技术的发展,数据清理将更加智能化、自适应,并能深度融合领域知识,从而更好地服务于知识发现与决策支持。
面向知识服务的大数据清理是一个系统化工程,需要结合数据质量理论、计算技术和领域知识。通过构建多层次的技术框架,并依托数据处理服务,可以有效提升数据价值,为知识服务提供可靠的数据基础。