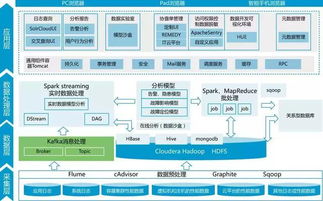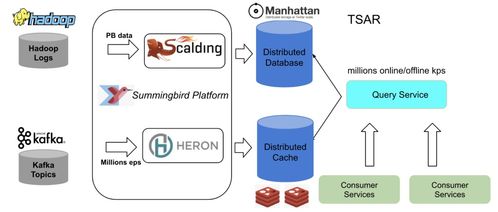
在数据处理服务领域,许多企业正从传统的Lambda架构和Twitter流处理方案转向基于Kafka与数据流的新架构。这一转变不仅提升了数据处理的效率,还带来了更好的可扩展性和实时性。
为什么需要弃用Lambda架构?Lambda架构虽然将批处理和流处理分开,但带来了系统复杂性高、维护成本大的问题。企业需要维护两套代码逻辑,导致开发周期长且容易出错。同时,Twitter的流处理解决方案在扩展性和容错性方面存在限制,难以应对高吞吐量的数据场景。
相比之下,Kafka作为分布式事件流平台,提供了高吞吐、低延迟的数据处理能力。结合现代数据流架构,如Apache Flink或Kafka Streams,企业可以实现统一的流处理和批处理模式,简化系统设计。Kafka的持久化存储和分区机制确保了数据可靠性和水平扩展性,而数据流技术支持复杂事件处理和状态管理。
新架构的优势包括:实时数据处理能力增强,支持从数据采集到分析的全流程;降低了运维复杂度,通过单一平台处理多种数据任务;提高了系统的弹性,能够快速适应业务变化。企业通过这一转型,不仅优化了资源利用率,还为AI和实时分析应用奠定了坚实基础。
从Lambda和Twitter转向Kafka与数据流新架构是数据处理服务演进的必然趋势。它助力企业构建更高效、可靠的实时数据处理系统,推动数字化转型的深入发展。